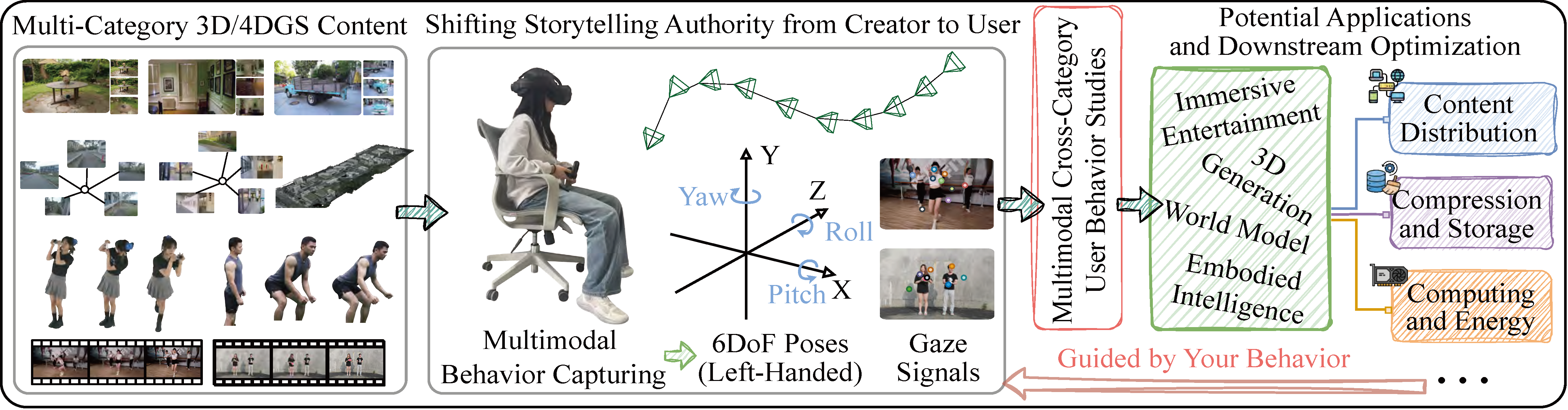
Figure 1: Illustration of downstream applications and services guided by multimodal cross-category user behavior analysis.
Figure 1: Illustration of downstream applications and services guided by multimodal cross-category user behavior analysis.
We present GSpark, a large-scale multimodal user-behavior dataset for 3D/4DGS viewing, covering diverse content across multiple categories<\strong> and capturing 6DoF poses and gaze data from 85 participants viewing 12 GS scenes using a commercial head-mounted display. We further detail the implementation of the data acquisition system and describe the test materials and viewing conditions employed during data collection. A comprehensive cross-category analysis is conducted to understand underlying behavioral mechanisms and uncover multiple key insights. Furthermore, we extensively evaluate viewport prediction as a representative application, revealing significant performance variations under diverse requirements.
A comprehensive comparison of existing user behavior datasets for photorealistic 3D/4DGS content viewing.
| Dataset | Static 3DGS | Dynamic 4DGS | User Behaviors | Non-Synthetic | Participants | Traces | |||
|---|---|---|---|---|---|---|---|---|---|
| Garden-scale | Large-scale | Human Avatar | Full-scene | 6DoF | Gaze | ||||
| L3GS [23] | ✓ | - | - | - | ✓ | - | - | 6 | 48 |
| SRBF [32] | ✓ | - | - | - | ✓ | - | ✓ | 3 | 24 |
| LTS [22] | - | - | ✓ | - | ✓ | - | - | 4 | 8 |
| EyeNavGS [3] | ✓ | - | - | - | ✓ | ✓ | ✓ | 46 | 552 |
| ViewGauss [33] | - | - | ✓ | - | ✓ | - | ✓ | 35 | 140 |
| GSpark (Ours) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 85 | 1020 |
In alignment with recent advances, four categories of GS content stimulus are selected for user behavior collection and analysis, covering the major research domains of GS representation. "10 × 5” in “ViewTime” denotes a 10 s video repeated five times.
| Category | Content Name | Label | Area / Scale | ViewTime |
|---|---|---|---|---|
| Garden-scale 3DGS Scene | Garden [1] | Outdoor | 400 m² | 120 s |
| Truck [15] | Outdoor | 80 m² | 120 s | |
| DrJohnson [8] | Indoor | 60 m² | 120 s | |
| Large-scale 3DGS Scene | Gallery [18] | Indoor | 2,500 m² | 120 s |
| Campus [13] | Outdoor | 55,000 m² | 120 s | |
| CUHKLower [27] | Aerial | 1.020 km² | 120 s | |
| Dynamic 4DGS Human Avatar | DNA08_01 [28] | Dancer | — | 5 × 6 s |
| DNA13_09 [28] | Photog | — | 5 × 6 s | |
| Sport_2 [25] | Player | — | 6 × 6 s | |
| Dynamic Full-scene 4DGS | Dance_3 [28] | Perform | 10 m² | 10 × 5 s |
| Actor1_4 [17] | Interact | 10 m² | 6 × 6 s | |
| Actor2_3 [17] | Interact | 10 m² | 6 × 6 s |
Our data acquisition prototype uses an HTC VIVE Focus 3 Vision HMD with dual eye-tracking cameras. The system integrates with Unity via OpenXR, communicating with a Python-based proxy renderer that supports heterogeneous GS representations (3DGS & 4DGS) via UDP. As the maximum refresh rate supported by the hardware varies with scene scale, we record user 6DoF poses and gaze signals at a sampling rate of approximately 25–45 Hz using an automated logger. Note that 4DGS playback preserves the original video frame rate (FPS), while user behavior is sampled at a higher rate. All GS models are rendered at the original 1:1 scale to preserve geometric fidelity.
We recruited 85 participants (50 female, 35 male) with normal/corrected vision. Each participant viewed all 12 GS stimuli in randomized category order. The experiment comprised: (1) Preparation & IPD calibration, (2) Interactive viewing with free 6DoF exploration, (3) Post-questionnaire (demographics and immersion). Behavioral data was automatically logged without interruption. As the survey in Table, most participants were first-time users or had limited XR experience, yet they reported relatively high mean opinion score (MOS) values for immersion.
| Demographic | Statistics |
|---|---|
| Gender | 40 F / 35 M |
| Age range | 19 – 56 years |
| Limited XR Experience | 94% (80 Participants) |
| Immersion Score (MOS) | 74% Participants ≥ 4 (Good) |
| Total Valid Traces | 1020 (85 × 12 scenes) |
The dataset follows a hierarchical folder structure for easy navigation:
ROOT/
├── Stimuli (Viewing Frames)/ # sample rendered images of each scene
│ ├── "Content Name"_"Label"/
│ └── ...
├── "Category"_UserBehavior/
│ ├── "Content Name"_"Label"/
│ │ └── "UID"_"Content Name".csv
├── ...
├── Readme.md # acquisition parameters, coordinate system, equipment details
└── LICENSE.txt
Each CSV includes columns: Timestamp (ms), Scene_X/Y/Z (meters), Head_RotX/Y/Z (degrees), Eye_X/Y/Z/W (quaternion). The README file provides comprehensive documentation on coordinate conventions and usage.
GSpark is freely available for academic research. The dataset includes all raw CSV traces, scene metadata, and documentation.
Please read the Readme.md for folder structure and usage. If you encounter access issues, verify your Google account or contact the maintainers.
📜 License: The Creative Commons Attribution 4.0 International (CC BY 4.0) license.
If you use GSpark in your research, please cite the following paper:
@inproceedings{gspark2026,
title={Guided by Your Behavior: A Large-Scale Multimodal User-Behavior Dataset for Understanding 3D/4DGS Interaction},
author={Jianxin Shi, Sijie Zhou, Tianshun Cai, Yili Jin, Yifei Zhu, Fangxin Wang, Lingjun Pu, Jiangchuan Liu},
booktitle={Under review},
year={2026}
}
Contact: jxshi{at}nankai{dot}edu{dot}cn
To investigate the aforementioned fundamental issues, we conduct a multi-perspective analysis of the collected multimodal user behavior data, with visualizations as follows:
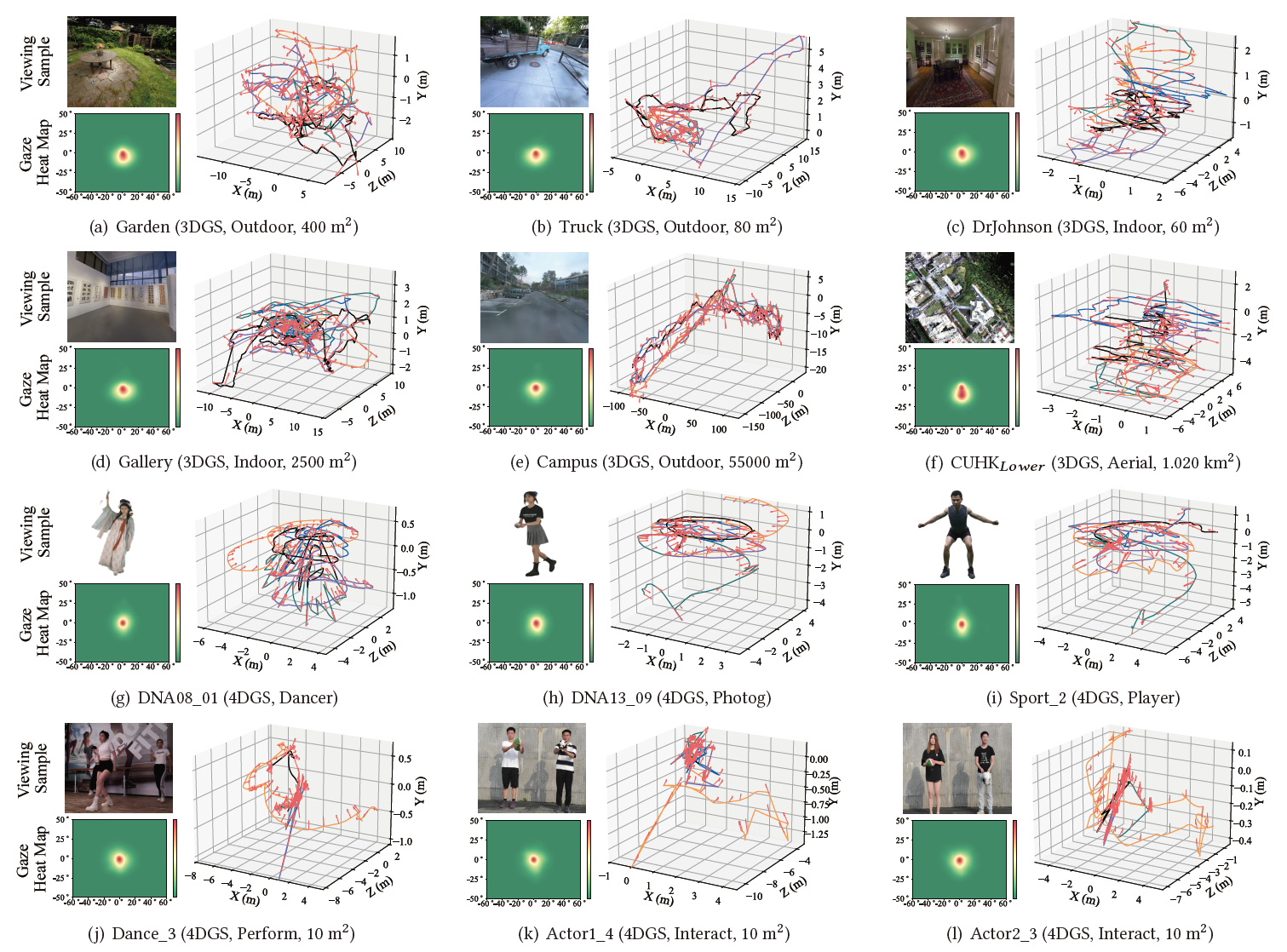
Figure 2: Trajectory and gaze signal analysis of multiple user behavior data. The viewing samples are rendered images generated by the 3D/4DGS models. Heatmaps represent the cumulative distribution of gaze positions. Head trajectories of five users (shown as lines in different colors) and viewing directions (indicated by red arrows) are illustrated in the 3D plots.
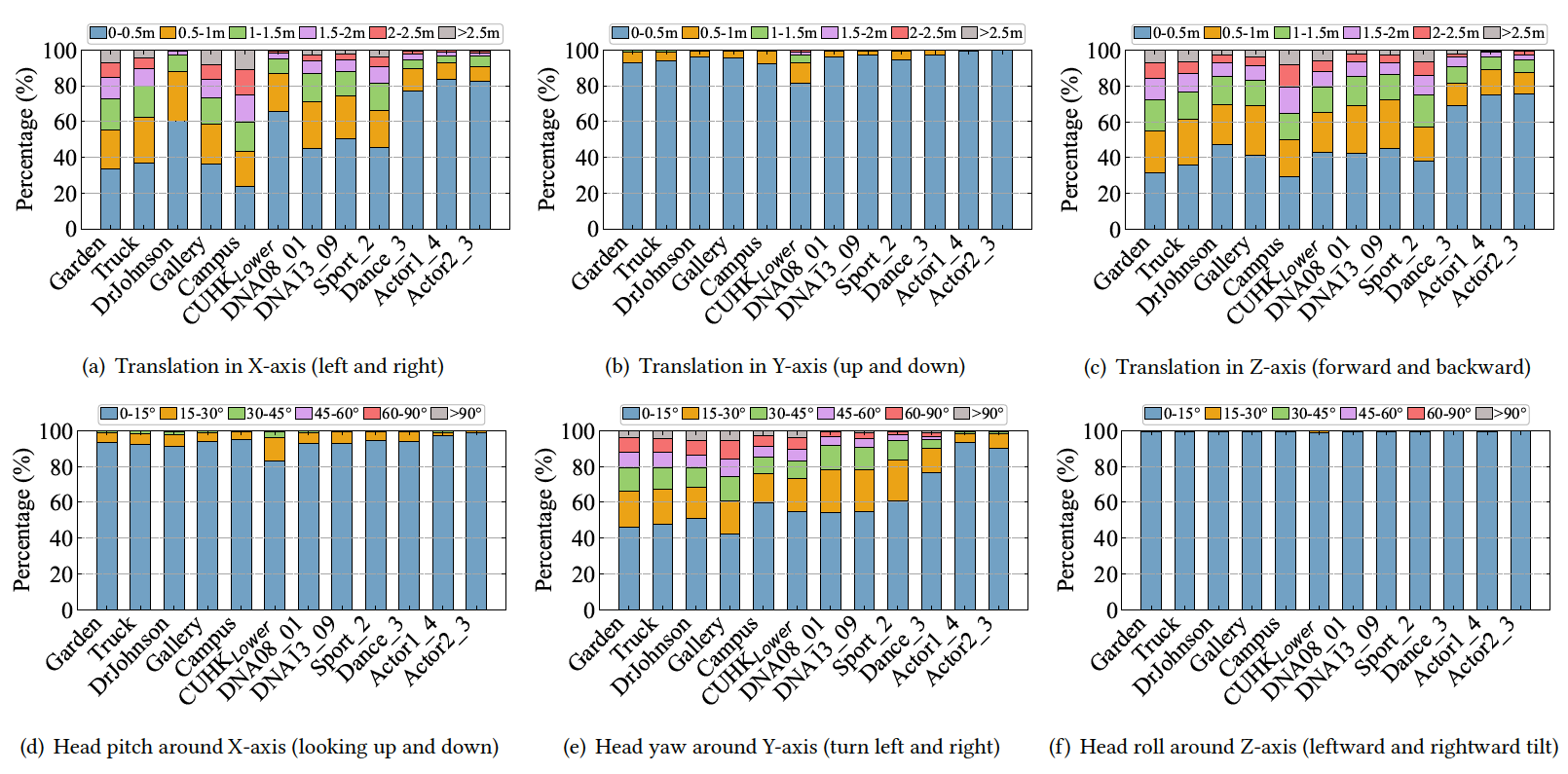
Figure 3: Percentage of participants reaching the maximum translation and rotation ranges within 3-second intervals.
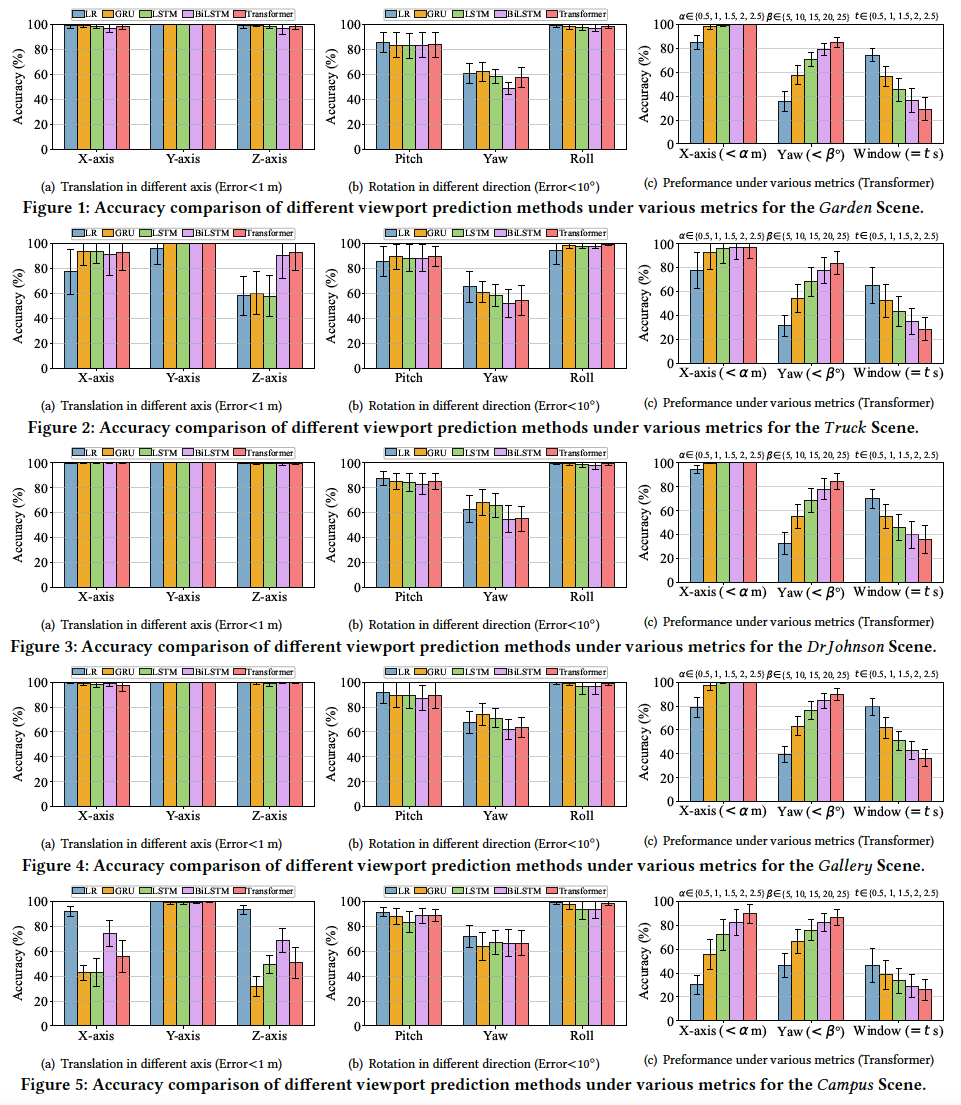
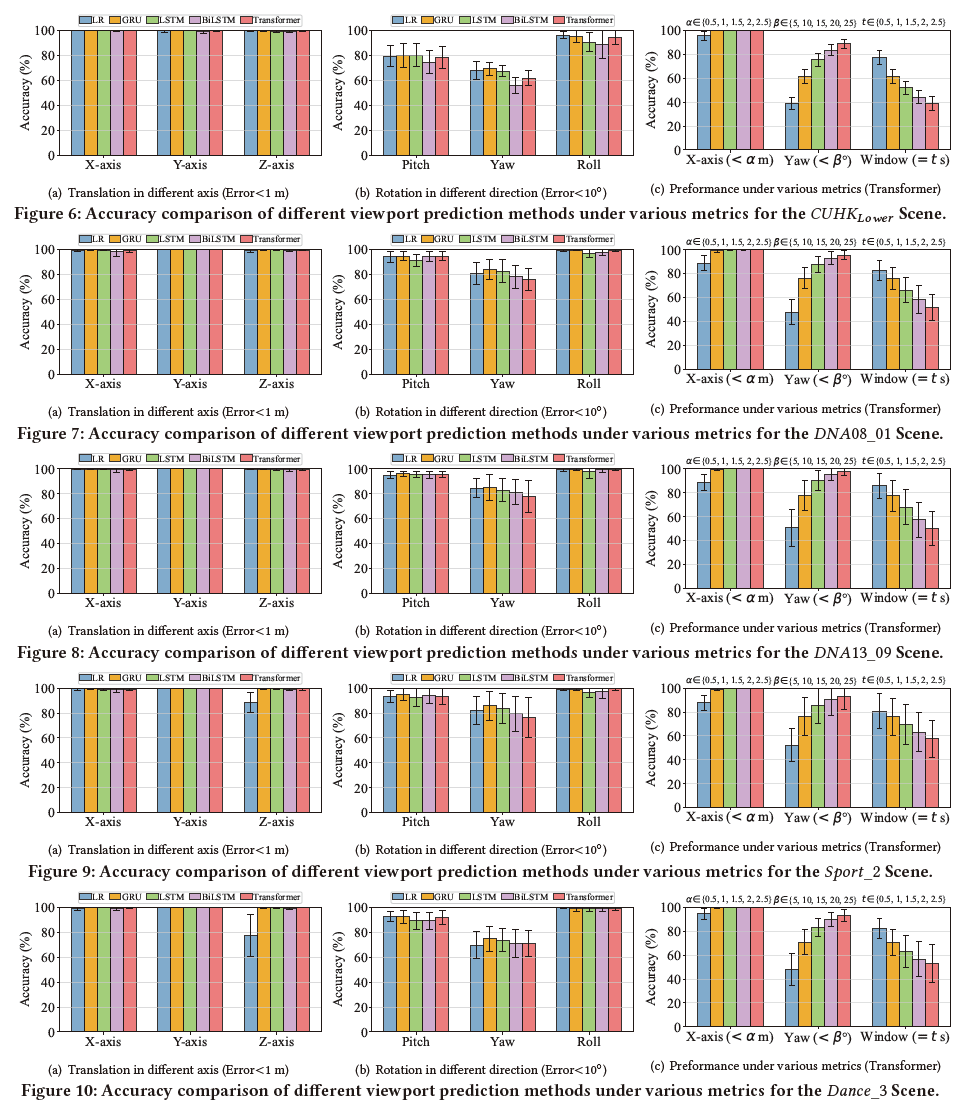
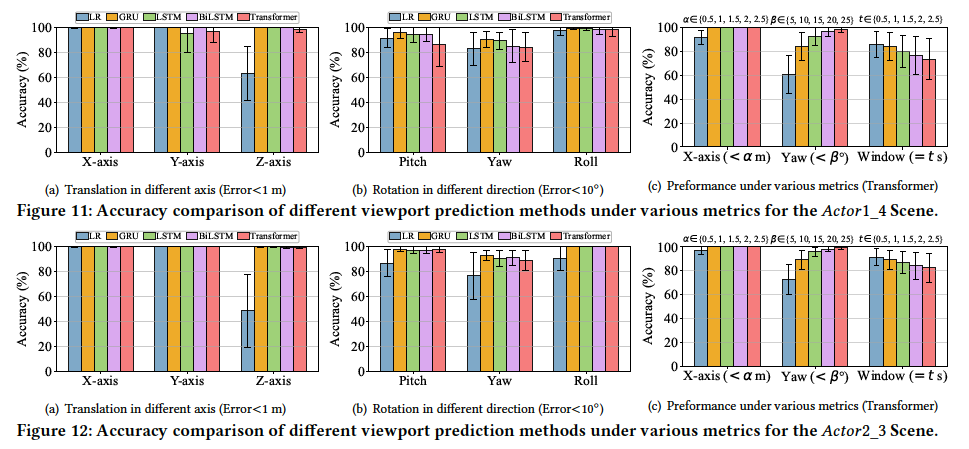
To further understand interactions in 3D/4D Gaussian Splatting, we employ the widely adopted viewport prediction (VP) task as a pilot study, serving as a foundation for downstream user behavior-aware optimization. Considering the temporal dependencies in user behavior, we adopt several representative time-series-based models to predict future user behavior, including linear regression (LR), gated recurrent units (GRU), long short-term memory (LSTM), BiLSTM, and Transformer-based models. For each scene, 80% of the traces are used for training, and the remaining 20% for evaluation. Both 6DoF pose and gaze signals are jointly used as inputs for predicting future user poses (viewport). Unless otherwise specified, VP performance is evaluated using metrics of translation error < 1 m, rotation error 10°, and predicted window =1 second. The results for each scene are shown as follows: